The Ultimate Guide to OpenClaw Memory: From Broken to Production-Ready
The Ultimate Guide to OpenClaw Memory
Source: https://x.com/lijiuer92/status/2025678747509391664 Author: @lijiuer92 Published: 2026-02-22 Stats: 👍 1,034 | 🔁 243 | 👁 337,344
Every time your OpenClaw agent loses its memory, it's not just burning your money — it's killing your workflow. You're afraid to restart it.
I read 10+ agent memory research papers and surveyed 6 open-source projects with a combined 77K GitHub stars. Here's a complete breakdown of every layer of the OpenClaw memory problem — from current state to solutions, from academic research to engineering.
Part 1: The Brutal Reality — Your Agent Has Goldfish Memory
Start with a number: 45 hours.
GitHub Issue #5429 reporter EmpireCreator lost 45 hours of accumulated agent context: skill configs, integration parameters, task priorities. A silent compaction wiped all conversation history — no warning, no recovery option.
This isn't an edge case. Issue #2624 reports agents randomly resetting and forgetting conversations from 2 messages ago. Issue #8723 reports a memory flush triggering an infinite loop that locked an agent for 72 minutes.
OpenClaw's current memory architecture in one sentence: Markdown files + vector search.
- Daily Logs — short-term journal
- MEMORY.md — long-term memory
- SOUL.md — personality definition
- Retrieval via vector embeddings + BM25 hybrid search
The problem? Three words: flat, undifferentiated, passive.
All memories carry equal weight. A casual chat from a year ago gets treated the same as a critical decision from yesterday. Forgetting mechanism? Doesn't exist — manual deletion only. Retrieval only looks at semantic similarity, not importance.
Part 2: What OpenClaw Is Building — QMD and Hybrid Search

Official release timeline for Jan–Feb 2026:
- v2026.1.12: Vector search infrastructure ships — SQLite index + chunking + lazy sync + file watching
- v2026.1.29: L2 normalization fix — local embedding vectors weren't normalized, causing cosine similarity distortion
- v2026.2.2: QMD memory backend merged (PR #3160) — BM25 + vector + reranking three-way hybrid search
What QMD does: replaces the built-in SQLite indexer with a local search sidecar process, supports multiple named collections, session records can be exported and indexed.
Known issues: CPU-only systems take ~3 min 40 sec per query (well over the 12-second timeout). Fallback is silent — users don't know when QMD isn't working.
The core problem with the official direction: all of this is retrieval-layer optimization. Forgetting, importance scoring, knowledge graphs, reflection, temporal reasoning, memory promotion — none of it is addressed.
Part 3: How the Community Is Coping — Five DIY Approaches

The community didn't wait. At least 7 third-party memory projects appeared in Jan–Feb 2026:
1. Mem0: Auto-Recall searches relevant memories before each response and injects them into context. Auto-Capture extracts facts after each response and stores them. Claims 91% latency improvement and 90% token savings.
2. Hindsight: Fully local, PostgreSQL backend. Key insight: traditional systems give agents a search_memory tool, but the model doesn't always use it. Auto-Recall solves this by injecting automatically.
3. MoltBrain (365 stars): SQLite + ChromaDB semantic search, lifecycle hooks for automatic context capture, web UI for timeline browsing.
4. NOVA Memory System: PostgreSQL structured memory with 8 database tables (entities, relationships, locations, projects, events, lessons, preferences).
5. Penfield Skill: BM25 + vector + graph hybrid search — the community already built three-way hybrid search independently.
Six areas the community hasn't touched at all: forgetting/decay mechanisms, importance scoring, knowledge graphs, automatic reflection/consolidation, temporal reasoning, memory promotion.
Part 4: The Academic Explosion — 10+ Papers in February 2026
February 2026: agent memory suddenly became a hot research area. 10+ papers appeared on arXiv in a single month.
xMemory [1] (ICML 2026): Decouples memory into semantic components organized into a hierarchy.
A-MEM [2] (NeurIPS 2025): Applies the Zettelkasten method to agent memory — dynamic indexing and linking to create an interconnected knowledge network.
TAME [5]: Identifies a critical danger — "Agent Memory Misevolution." Memory can accumulate "toxic shortcuts" through normal task iteration.
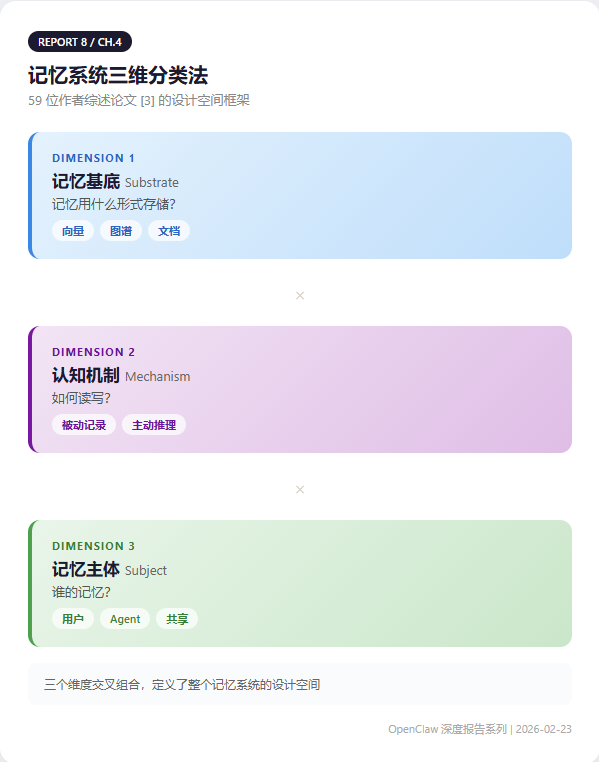
A 59-author survey paper [3] proposes a three-dimensional taxonomy:
- Substrate: vectors, graphs, or documents?
- Mechanism: passive recording or active reasoning?
- Subject: user's memory, agent's memory, or shared?
Two key warnings from industry:
- Serial Collapse (Moonshot AI Kimi K2.5): agents degrade into not using memory at all
- Memory Misevolution (TAME): toxic shortcuts accumulate through normal iteration
Part 5: The Open-Source Ecosystem — 6 Projects Compared
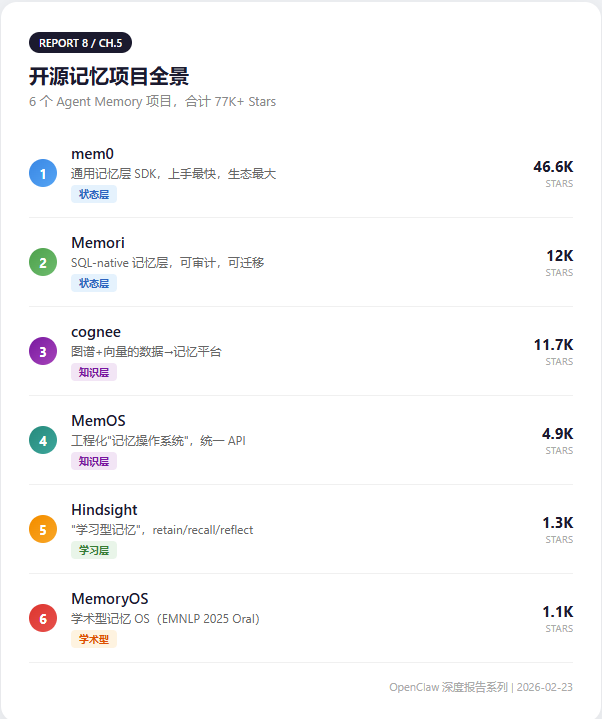
Six projects with a combined 77K+ stars represent three completely different memory philosophies:
| Philosophy | Projects | Core Positioning |
|---|---|---|
| State-layer first | mem0, Memori | Memory = state management |
| Knowledge-layer first | cognee, MemOS | Memory = structured knowledge |
| Learning-layer first | Hindsight | Memory = learning process |
No single project covers all three layers.
Part 6: Lessons from 200+ Issues — Mistakes Already Made
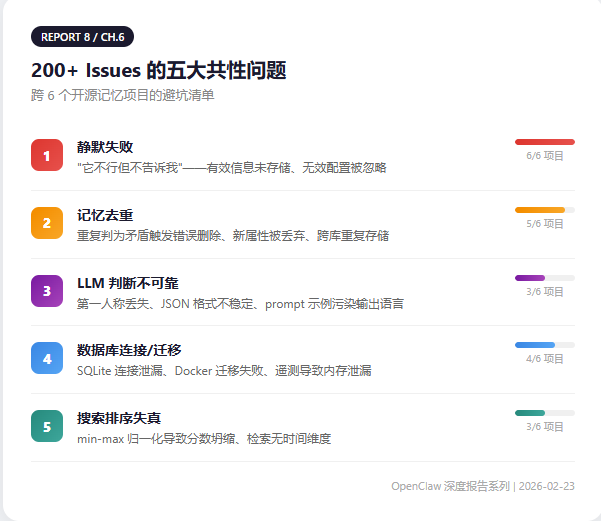
Five common failure patterns across projects:
1. Silent failure (present in all 6 projects): Users' biggest complaint isn't "the feature doesn't work" — it's "it doesn't work and doesn't tell me."
2. Memory deduplication is a universal pain point: LLMs interpret duplicate content as "contradictions" and incorrectly delete things.
3. LLM judgment is unreliable: "My name is Wang Muchen" loses its first-person reference after LLM paraphrasing.
4. Database connection/migration issues: SQLite connections never close, causing "database is locked" errors.
5. Search ranking distortion: Cross-collection min-max normalization causes ranking distortion.
Part 7: What Game AI Got Right
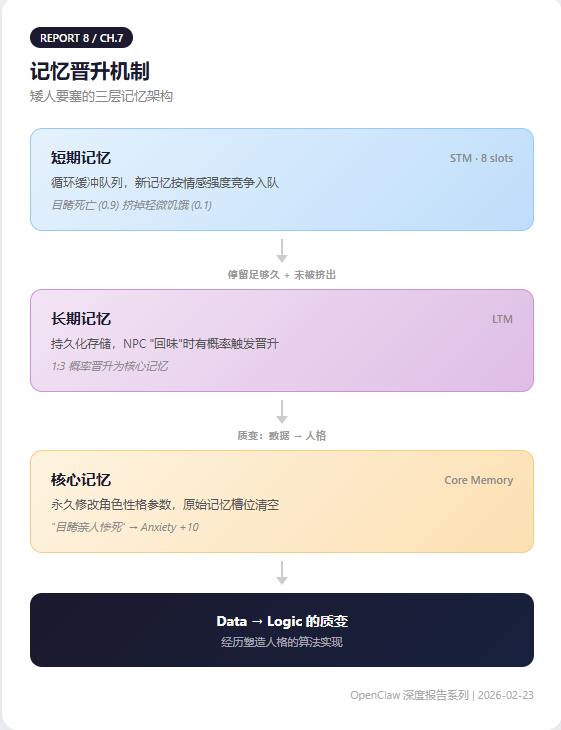
The most underrated reference isn't academic papers — it's game AI.
Dwarf Fortress's three-layer memory architecture:
- Short-term memory (STM): 8-slot circular buffer queue, new memories compete by emotional intensity
- Long-term memory (LTM): STM entries that persist long enough get promoted
- Core memory: qualitative change — permanently modifies character personality parameters
Stanford Generative Agents' three-dimensional retrieval:
Retrieval score = Recency × Importance × Relevance
Recency uses exponential decay. Importance is LLM-scored (marriage=10, a walk=2). Reflection mechanism: take the 100 most recent trivial memories → LLM distills 3 high-level insights → stored as new memories. Long-term conversational fact recall improved from 41% to 87%.
Part 8: Two Kinds of Memory — User Memory vs Agent Memory

User memory and agent self-memory are two completely different problems.
ByteDance OpenViking's classification: 6 memory types (profiles, preferences, entities, events, cases, patterns) + L0/L1/L2 three-tier content model:
- L0 summary ~100 tokens for indexing and deduplication
- L1 overview ~500 tokens for structured presentation
- L2 full content retrieved only when needed
Part 9: Memory Is the Core of the 24/7 Agent War

Whoever solves memory first wins the 24/7 agent war.
Three converging forces in February 2026 — academic paper density, open-source project explosion, official architecture upgrades — all point to the same signal: AI memory is moving from "nice to have" to core infrastructure.
References
- [1] xMemory: Beyond RAG for Agent Memory, ICML 2026. arXiv:2602.02007
- [2] A-MEM: Agentic Memory for LLM Agents, NeurIPS 2025. arXiv:2502.12110
- [3] Rethinking Memory Mechanisms of Foundation Agents, arXiv:2602.06052
- [4] InfMem: Learning System-2 Memory Control, arXiv:2602.02704
- [5] TAME: Trustworthy Agent Memory Evolution, arXiv:2602.03224
- [10] Generative Agents: Interactive Simulacra of Human Behavior, arXiv:2304.03442
Original post: https://x.com/lijiuer92/status/2025678747509391664 | via @lijiuer92